Let’s quickly go over some useful stdlib provided data structures and algorithms that come in handy in Competitive Programming.
Input / Output Streams (cin, cout)
C++ introduces the concept of “streams” to supercede the older printf and scanf implementations in C. In short, streams are an abstraction of a construct used to refer to input / output sources of an unknown number of bytes. You can think of each source as a “river”, that carries water (data) from some glacier (source, ex: keyboard, file, etc.) to a dam (buffer), from where you can consume water (parse and read input) at your convenience. Think of an user typing at a keyboard or data received over a socket connection, we do not know how many bytes we will receive or when the input will end, they’re all streams we can listen to. In more “data-structure” terms, a stream is simply a queue. Input arrives at the end of the queue, and we read from the front of it.
It’s important to note that the above explanation of a stream is just a concept. In C++ terms, streams are implemented as classes. std::cin and std::cout are just global objects of type std::istream and std::ostream which are guaranteed to be initialized and tied to the input and output streams respectively. So how exactly is the below code parsed and executed?
intx=10;std::cout<<x<<'\n';
The << operator, which you might recognize as the binary left shift operator has actually been overloaded to accept objects of the type std::ostream and int and also char*. Essentially, it translates to:
((std::cout<<x)<<'\n');
This is essentially the signature of what an overload for a generic type T would look like.
operator<<(std::ostream&os,Tx){os<<x;// Obviously, do something else here with x
returnos;}
So in the above example, we first evaluate the inner expression (std::cout << x). << acts on cout and x, printing the value of x to stdout and then returns the output stream std::cout again. The expression now becomes std::cout << '\n, which is evaluated by printing '\n' to stdout.
Similarly, for reading input, we use std::cin >> x.
Why not stick with scanf / printf?
So why the new fancy streams? Why not stick to C-style scanf and printf? There are several reasons. We’ll go over them below.
Type Safety
Both printf and scanf rely on a “format string” to provide the matching type for provided variadic arguments. This creates a huge decoupling in type information and it is very easy for the function to break due to incorrect format strings being provided. With cin and cout, the << operator is overloaded by each type that is being passed to it and hence it automatically picks the right overload for the datatype it’s instructed to print. If we pass a datatype that is neither primitive nor has this overload defined, we get a safe compile-error.
More “Extensible”
I’ll use the word ’extensible’ instead of ‘object oriented’ here, but essentially, since << and >> are just operators that accepts stream objects and the datatype to print, it is easy for any other larger struct or class object in C++ to overload this operator for printing purposes. The alternative in C would be to define a print_type_a function for each such type. Note that this is also not inheritable. Whereas in C++, as long as the class had it defined, we can just do cout << obj;. Better for implementation hiding, etc.
Supposedly, this is supposed to be safe. But if the user enters the string “abc”, then a “10”, you’ll notice you’re stuck in an infinite while loop. This is because scanf never reads any input that it fails to parse. In this case, since stdin has the string “abc” at the beginning, it fails to parse it using %d conversion to an integer and hence “abc” stays at the beginning of stdin for all further iterations of this loop. You might think the correct solution is to clear the buffer before calling scanf again, but this is horribly wrong. Because according to the C standard, fflush is meant to only be called on an output stream. Essentially, fflush(stdin) is undefined behavior (But it works on my machine! - Beginners guide to Undefined Behavior in C++). You’d need to read wrong input into a char buffer instead. But then you run into issues where the input string might exceed the length of your buffer, etc.
The summary is that scanf is very easy to use incorrectly. It’s a powerful function that is very easy to get wrong. This is how you’d correctly use scanf for the above example:
#include<stdio.h>intmain(void){intx,ret;/** Since we want exactly one integer read, success for us is when ret == 1.
* If ret is 0, we had an early matching failure and need to clear the rest of stdin.
* To do this, we instruct scanf to **parse** everything left in stdin using "%*[^\n]",
* - %* tells scanf to do the reading and not store it anywhere. This is to avoid buffer overflow.
* - [^\n] tells scanf to parse everything until it encounters the newline character
*/while((ret=scanf("%d",&x))==0)scanf("%*[^\n]")// Now, we still might have to deal with errors
if(ret==EOF){if(feof(stdin))puts("End of file reached");elseperror("Read error");}elseprintf("x = %d",x);}
Clearly, it’s pretty easy to mess this up unless you spent a good amount of time carefully reading the scanf man page. And this is a very simple example, things can get more complicated when we have to parse more complicated input. With cin, things are easier (a bit).
#include<iostream>
intmain(void){intx;/** On receiving bad input, cin automatically sets the cin.fail() flag to true.
* Immediately all future calls to cin fail until this is cleared using cin.clear()
* We then clear up the stream as before.
*
*/while(!(cin>>x)){cin.clear();// Clear the error bit
cin.ignore(numeric_limits<streamsize>::max(),'\n');// Clear up stdin
}cout<<"x = "<<x<<"\n";}
Things are harder to get wrong. cin automatically fails future reads, and there are safe ways to clear the remnants of stdin. Further, thanks to overloading and inheritance, it is very easy to abstract away and hide these methods in implementation details when required.
What is fast io?
When dealing with problems where your C++ program needs to read and write a lot of input, you are suggested to speed up IO by adding these two lines to the start of the program (before any calls to IO). What does it do and why does it magically “speed up” IO? Why isn’t it on by default? Let’s dissect each statement one at a time.
ios::sync_with_stdio(0);cin.tie(0);
ios::sync_with_stdio(0)
Since cin and cout were introduced as newer, more ‘modern’ ways to parse and print information, it was imperative that the developers allow users to migrate code bases from stdio based scanf & printf legacy code to more modern cin / cout code. This meant that there might exist stages in migration where the code bases uses both scanf and cin interchangeably to read input from stdin. These scenarios should be handled as expected and not result in nasty surprises for the developers of these code bases. This was an important point to consider when developing C++. This meant that iostream would have to spend extra operations synchronizing itself with the stdio buffer.
In practice, this means that the synchronized C++ streams are unbuffered, and each I/O operation on a C++ stream is immediately applied to the corresponding C stream’s buffer. This makes it possible to freely mix C++ and C I/O.
In addition, synchronized C++ streams are guaranteed to be thread-safe (individual characters output from multiple threads may interleave, but no data races occur).
If the synchronization is turned off, the C++ standard streams are allowed to buffer their I/O independently, which may be considerably faster in some cases.
By default, all eight standard C++ streams are synchronized with their respective C streams.
For this part, there’s an excellent comment by user -is-this-fft-, on Codeforces that explains this line much better than I can. I’ll just quote his explanation here:
I think it would be good to reiterate what tie does because I see a lot of people copying these lines with only a vague understanding of what they do.
Every stream in C++ is tied to an output stream, which can be null.
What does this mean? First of all, it’s important to understand that when you write std::cout << "asdf", it is not necessarily immediately printed on the screen. It turns out that it is much better (in terms of performance) to collect it into a buffer and then, at some point, flush the buffer — i.e. empty its contents to the screen (or file, or any other “device”), all at once.
But now, consider the following. You are developing a console application and write something like:
1 std::cout << "Please enter your age: ";
2 int age;
3 std::cin >> age;
What would happen if std::coutdidn’t get flushed before line 3? The program would expect a reply from the user, but the user hasn’t even had a chance to read the question. In an application like this, it would be a good idea if std::cout was somehow automatically flushed when we try to read from std::cin.
And this is exactly the problem tie solves. If you have two streams fin and fout, and fin is tied to fout, then fout is automatically flushed when you try to read from fin. So what are the defaults? What is tied to what? Quoting the C++ reference:
By default, the standard narrow streams cin and cerr are tied to cout, and their wide character counterparts (wcin and wcerr) to wcout. Library implementations may also tie clog and wclog.
Now it becomes clear why people recommend using cin.tie(0) in competitive programming. Suppose you are solving a query problem like this.
1 MyAwesomeDataStructure ds;
2 for (int i = 0; i < queryc; i++) {
3 Query q;
4 cin >> q;
5 cout << ds.solve(q) << '\n';
6 }
If you didn’t use cin.tie(0), we would flush cout every time we hit line 4; this is essentially as bad as writing endl on line 5. Concerns about the user not seeing the question are also irrelevant now because we are given the entire input at once.
The reference doesn’t explicitly say that cout isn’t tied to anything, but on every C++ compiler I tried, cout << cout.tie() << endl; outputs 0. Also, even if you are using some strange compiler that ties cout to some other stream sout, you would only notice the performance hit if you wrote a lot to sout which doesn’t really happen in competitive programming.
Probably the single most amazing feature C++ has to offer for competitive programmers. When solving problems, you’ll often encounter situations where you will need to use data structures like balanced binary search trees, hash tables and priority queues or algorithms like ($nlogn$) sorting, binary search, etc. for coming up with efficient solutions.
Containers
STL provides you with the Containers Library to help in these situations. Thank’s to Templates in C++, they makes implementing such data structures for any kind of data extremely easy to quick to implement. And unlike certain other languages, C++ guarantees complexity requirements for all standard library implementations to follow, so you have portable code efficiency guarantees. Further, containers provide a great layer of abstraction for us to work with types more generically. For example, all containers (bar minor exceptions) provide constant time access to their size via the .size() member function. This returns the number of elements in the container. They also provide access to .begin() and .end() which provide constant time accesses to the first, and one-after-the-last elements of the container via iterators (What are Iterators in C++?). In C++, iterators serve as a bridge between containers and algorithms in the STL. They abstract away container-specific details, allowing algorithms to work with any container type. By focusing only on the iterator type, STL algorithms ensure the right operations are performed efficiently (choosing the right complexity overloads using SFINAE), regardless of the container’s underlying data structure & implementation details.
You can check out all the other details regarding container requirements on either cppreference or from N3797 (from pg 741 in the PDF).
We’ll start by discussing the most popular ones in short.
std::array
An array in C++ is something like a simple C++ template wrapper around C-style arrays. As a consequence, std::array can only be used to create fixed size arrays. Further, it is also stack allocated. A common trap here is to sometimes create C-style arrays or std::array in deep recursive functions. In such situations it’s usually fine for recursion depth if each function frame isn’t very large, but due to the these arrays being stack allocated, each frame contains a large stack allocated array, making the frame size pretty large and causing the recursive function to break the stack limit. Can fix by increasing stack limit (ulimit -s unlimited) or by using heap allocated containers.
This container is an aggregate type with the same semantics as a struct holding a C-style array T[N] as its only non-static data member. Unlike a C-style array, it doesn’t decay to T* automatically. - array - cppref
Note that in the above code block, $A$ is default-initialized. For primitive types like int, this means that the values are indeterminate / undefined until set. If we want to value-initialize them, we can declare the array using std::array<int, 4> A{} instead. For integers, this would initialize all elements to 0.
std::vector
A vector in C++ is a sequence container.
Sequence containers implement data structures which can be accessed sequentially. - Container - cppref
std::vector is very similar to std::array in that they are both made to model contiguous homogeneous array data, with one key difference. While std::array is fixed size and stack allocated, std::vector can dynamically expand and shrink as required, at the expense of slightly increased memory and time usage. Note that the time complexity for all functions is still the same as that of std::array (amortized), but it has slightly higher constant factor. This is because unlike std::array, std::vector is heap allocated, which means creating a std::vector involves making system calls to the underlying memory management system (brk / mmap). Further, to allow dynamic expansion / shrinking (from the end) while allowing for amortized constant time complexity, it needs to allocate some extra space and carry out a few copy operations at chosen intervals. You can watch this wonderful video by MIT OCW - Erik Demaine - Data Structures and Dynamic Arrays to understand how this amortized constant time complexity is achieved. Further, this is implied but std::vector supports constant time random accesses.
Useful functions
push_back: Inserts an element x at the end of the vector, $O(1)$ amortized.
pop_back: Deletes the element at the end of vector, $O(1)$ amortized.
std::vector<int>A(4);// Automatically initializes to 0. Equivalent to A(4, 0).
A[0]=1,A[3]=2;// auto [a, b, c, d] = A <- Does not work since size of A is not a compile time constant
A.push_back(5);A.push_back(5);A.pop_back();for(auto&x:A)cout<<x<<' ';// Output: 1 0 2 0 5
std::deque
std::deque (double-ended queue) is an indexed sequence container that allows fast insertion and deletion at both its beginning and its end. In addition, insertion and deletion at either end of a deque never invalidates pointers or references to the rest of the elements. - deque - cppref
With std::vector, we can insert / delete from the end of the dynamic array in constant time, but insertion / deletion from the front is linear. std::deque tries to solve this problem by allowing fast insertion and deleting at both ends. Further, unlike with std::vector, it is not amortized complexity. Both insertion and deletion at either end are constant $O(1)$.
So what’s the catch? It’s “constant”, in quotes. In practice, most std::deque implementations store sequences of individually allocated fixed-size arrays. Combing some sort of hashtable-esque bucket structure to fixed size arrays. This means that there is a significant amount of extra bookkeeping and pointer dereferences to perform. You can read this wonderful answer by Konrad Rudolph on StackOverflow to get a better idea of how it’s implemented.
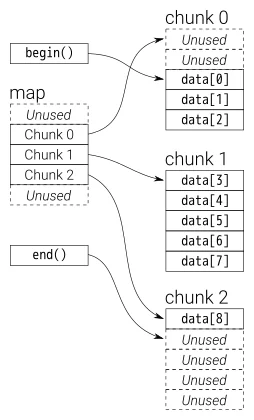
A deque is somewhat recursively defined: internally it maintains a double-ended queue of chunks of fixed size. Each chunk is a vector, and the queue (“map” in the graphic below) of chunks itself is also a vector.
There’s a great analysis of the performance characteristics and how it compares to the vector over at CodeProject.
The GCC standard library implementation internally uses a T** to represent the map. Each data block is a T* which is allocated with some fixed size __deque_buf_size (which depends on sizeof(T)).
You can take a look at this report by Nitron at the above quoted link, An In-Depth Study of the STL Deque Container - Code Project to get a better idea of just how slow the constant factor is. In practice, there have been instances where an Iterative segment tree solution (with it’s extra $log(n)$ factor) was able to get a faster execution time than the linear time std::deque. This could’ve been poor tests, but also serves as a reminder to only use this data structure when absolutely required.
Useful functions
push_back: Inserts an element x at the end of the std::deque, constant $O(1)$.
pop_back: Deletes the element at the end of the std::deque, constant $O(1)$.
push_front: Inserts an element $x$ at the beginning of the std::deque, constant $O(1)$.
pop_front: Deletes an element at the beginning of the std::deque, constant $O(1)$.
front: Returns a reference to the first element in the container, constant $O(1)$.
back: Returns a reference to the last element in the container, constant $O(1)$.
std::queue is well, a queue. It uses std::dequeue as it’s underlying container and just acts as a wrapper getting rid of the functions which allow insertion in the beginning and deletion at the end.
std::set
Alright, we’re done with all the important sequence containers now. We’ll now be dealing with associative containers.
Associative containers implement sorted data structures that can be quickly searched (O(log n) complexity).
std::set is an associative container that somewhat models the mathematical definition of a set. Therefore, at all points, a std::set will only contain unique elements. std::set is usually implemented as some variant of a balanced binary search tree (red-black trees are a popular choice). However, note that all implementations are very heavy since they often involve multiple pointer dereferences and balancing operations in the background. This means that you should avoid this data structure if possible. But regardless of underlying data structure, std::set provides you with the following functions and efficiency guarantees:
Useful Functions
insert: Allows insertion into the sorted set in $O(log(n))$ time. (Amortized $O(1)$ if you provide the iterator to the element just less than $x$ in the set)
erase: Allows deletion from the sorted set in $O(log(n))$ time. ($O(1)$ if you provide the iterator to the element).
find: Allows searching the set for a matching element $x$ in $O(log(n))$ time
count: Returns the count of the elements in the set. Since a set contains only unique elements, this is $log(n)$ and the result is always 0 or 1.
begin: Returns an iterator to the first element of the std::set. Constant $O(1)$ time.
end: Returns an iterator to the element following the last element of the set. Constant $O(1)$ time.
lower_bound: Returns an iterator pointing to the first element that is not less than (i.e. greater or equal to) the given element $x$. $O(log(n))$ time.
upper_bound: Returns an iterator pointing to the first element that is greater than the given element $x$. $O(log(n))$ time.
A multi-set is a variant of std::set which let’s you store multiple copies of equal elements. There is primarily only one important change to note:
count: Returns the count of the elements in the multi-set. The time complexity is now logarithmic in the size of the container plus linear in the number of elements found. That is, $O(log(n) + f(x))$ where $f(x)$ is the frequency of element $x$ in the multi-set.
std::map
This is also a sorted associative container similar to std::set. However, instead of storing single element keys, it stores key-value pairs. The structure stores the keys in sorted order. Hence all the same useful functions of std::set are applicable for a std::map, just that accessing the element with $key = k_1$, returns the value $v_1$ associated to key $k_1$.
Useful Functions
insert: Allows insertion into the sorted map in $O(log(n))$ time. (Amortized $O(1)$ if you provide the iterator to the element just less than $x$ in the map)
erase: Allows deletion from the sorted map in $O(log(n))$ time. ($O(1)$ if you provide the iterator to the element).
find: Allows searching the map for a matching element $x$ in $O(log(n))$ time
count: Returns the count of the elements in the map. Since a map contains only unique keys, this is $log(n)$ and the result is always 0 or 1.
operator[key] : Returns a reference to the value that is mapped to the given $key$, performing an insertion if such key does not already exist. $log(n)$ time.
This is the C++ equivalent of a hash table. The syntax is extremely similar to that of std::map, however, it unlike std::map, std::unordered_map does not maintain sorted order. It uses a default hash function to hash objects to buckets like a hash table. Note that this means, it has the exact same syntax (barring declaration and functions like lower_bound and upper_bound) as std::map, but it performs insertion, deletion and search in average constant time complexity. Here, the cost of these operations is the cost of hashing the key and inserting, deleting or searching the bucket it was hashed into. Note that for a hash function that is not dependent on runtime randomness, you can always reverse engineer the hash function used to create tests that blow up the runtime time complexity to $O(n)$ per insert / delete / search query. You can read more about how to blow up the standard std::unordered_map hash function here in this blog by neal on CF: Blowing up unordered_map, and how to stop getting hacked on it.
std::priority_queue
This is not a new container per-say, but still deserves a mention here. It is a container adapter that transforms the underlying container (by default, std::vector) to perform heap operations. This means, it uses the underlying std::vector container to implement a heap that supports constant $O(1)$ time look up of the largest element and $log(n)$ insertion / deletion (only from the top). Compared to std::set, it does not support $log(n)$ search or $log(n)$ deletion of a random element in the priority queue. It’s functions are strictly a subset of what std::set can do. So why bother using it? Because it’s much much faster than std::set in practice. Since the underlying container is a std::vector by default, it presumably uses $2\cdot i$ & $2\cdot i+1$ to access node $i$’s children and adjusts structure by iterating over parents using $p = \frac{i}{2}$. This makes it’s constant factor much faster than that of std::set. If you only need the subset of operations provided by std::priority_queue, only use std::priority_queue.
priority_queue<int>pq;// Use priority_queue<int, vector<int>, greater<>> for a min-heap
pq.push(2);pq.push(10);cout<<pq.top()<<'\n';// Output => 10
pq.pop();pq.push(1);cout<<pq.top()<<'\n';// Output => 2;
Algorithms
You can find the comprehensive list here, Algorithms Library - cppref. We’ll go over only a few useful (in CP) ones.
std::sort
Easily one of the most used. sort(a.begin(), a.end()) sorts the elements in the range $[begin, end)$ in $O(nlog(n))$ comparisons. It uses a combination of quick / heap sort. Implementation can vary between standard libraries, but it’s definitely very low constant. Accepts custom comparators as an additional lambda argument.
vector<T>a;// populate a...
sort(a.begin(),a.end(),[&](T&x,T&y){// some custom sorting logic. I'll just fill it in with the default comparator for this example.
returnx<y;});
reverse(a.begin(), a.end()) reverses the elements in the range $[begin, end)$ in $O(n)$ time.
std::unique
unique(a.begin(), a.end()) removes all except the first element from every consecutive group of equivalent elements from the range $[first, last)$ and returns a past-the-end iterator for the new end of the range. Popular use is as an alternative to using std::set to counting the unique elements in a vector.
They are both equivalent. (Note: You need to call std::sort before using std::unique for this use case.)
std::rotate
Performs a left rotation on a range of elements. Useful trick to avoid wasting time figuring out indices & code. Linear time.
Lambda’s
You can read more about lambda’s here and here until I get the time to fill this section up sometime in the future. I’ll leave below my absolute favorite use of lambdas in competitive programming.
intmain(void){// Reading input ----------------------------
intn,m;cin>>n>>m;vector<vector<int>>adj(n);for(inti=0;i<m;i++){intu,v;cin>>u>>v;u--,v--;adj[u].push_back(v);adj[v].push_back(u);}// A simple dfs -----------------------------
vector<int>vis(n);function<void(int)>dfs=[&](intv){if(vis[v])return;vis[v]=true;for(auto&to:adj[v])dfs(to);};dfs(0);// - Very simple and concise.
// - No need to declare global variables (risk of not clearing, ugly, etc.)
// - Only need to pass the changing state to the lambda. All other constant "metadata" are captured automatically.
}