Flynn's Taxonomy
Interactive Graph
Table of Contents
Flynn’s Taxonomy
It’s basically a categorization of different forms of parallel computing architectures.
- At level 1 you basically have single instruction single data stream. There’s a single instruction which acts on exactly one data element,
- Next up you have single instruction multiple data stream, this time around we have a single instruction acting on multiple data elements at the same time. The idea is to have a large set of registers on which we perform the same operation using larger “ALU’s” or SIMD units. GPU are also a good example.
- I won’t call this an upgrade but another alternative is multiple instruction single data stream. An example is pipeline architecture, although strictly speaking the data that passes through different stages of the pipeline does undergo changes.
- Last up is multiple instruction multiple data stream. Consider multiple cores acting asynchronously performing SIMD operations. That’s one such example. (Parallelism with OMP, Brent’s Theorem & Task Level Parallelism, etc.)
SIMD
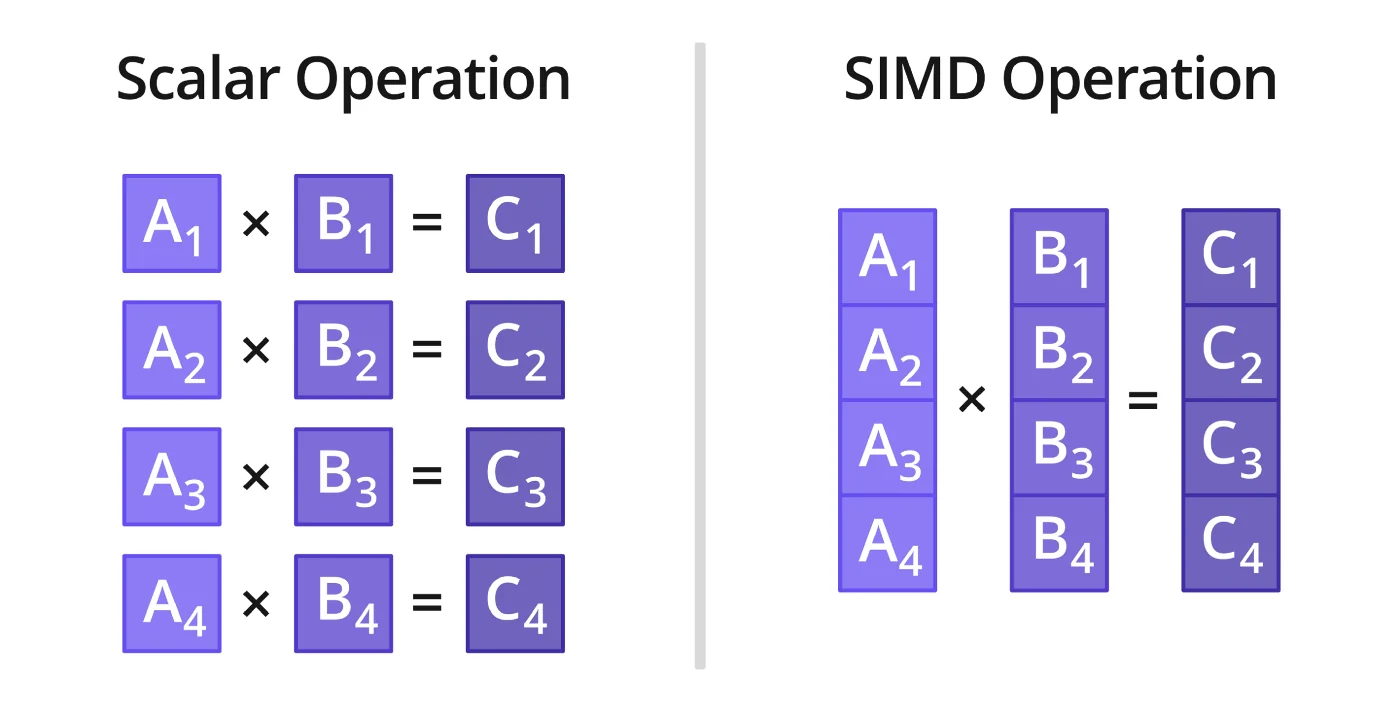
The idea here is to basically take multiple scalar instructions operating on adjacent pieces of memory and combine them into a single vector instruction which can apply the scalar operation element to element in a single instruction. In general SIMD operations have higher latency than their scalar counterparts but in exchange we get insane throughput. More on this in Vectorization & Analyzing Loop Dependencies.
Intel’s intrinsics guide contains the detailed documentation for all the different SIMD architectures and their corresponding SIMD instructions. Instead of requiring us to write assembly Intel exposes the intrinsic API via these library functions and these library functions generate the corresponding assembly. https://docs.nvidia.com/cuda/parallel-thread-execution/index.html
SPMD
SPMD → Single program multiple data. Distributed computing sort of works on this idea. Tasks are split up and run simultaneously on multiple processors with different input in order to obtain results faster. Note that the two are not mutually exclusive. Map Reduce.
References
These notes are quite old, and I wasn’t rigorously collecting references back then. If any of the content used above belongs to you or someone you know, please let me know, and I’ll attribute it accordingly.