Reasoning, Acting, and Learning : A Survey of Single-Agent LLM Patterns
Interactive Graph
Table of Contents
Large Language Models (LLMs) are fundamentally probabilistic engines designed to predict the next token. We’ve seen them achieve several impressive feats purely by throwing more data and compute at them. However, they still tend to occasionally hallucinate, have certain “model specific tendencies” etc. which are difficult to overcome purely by training. A recent popular example is Gemini 3, who’s performance varies by a sizable margin on coding tasks depending on the harness used to prompt it. There’s been a good bunch of research done in the space of prompting / agent architectures.
In this post, I’ll attempt to survey the academic literature surrounding single-agent reasoning strategies. From linear prompt engineering techniques like Chain-of-Thought (CoT) to more natural successors which are non-linear like Tree-of-Thoughts (ToT) and Graph-of-Thoughts (GoT). Finally, we will look at how to ground these “thoughts” in reality using Action loops (ReAct) and persistent “learnt” memory (Reflexion).
Evolving Single-Agent Reasoning Strategies: From CoT to GoT
This section focuses on improving single-agent LLM reasoning beyond simple Input-Output (IO) prompting.
Chain-of-Thought (CoT)
Chain-of-Thought Prompting Elicits Reasoning in Large Language Models [Google Research, Brain Team]
CoT at its core just suggests that LLMs are able to perform significantly better at solving hard ‘reasoning’ problems such as arithmetic, common-sense reasoning and symbolic reasoning when prompted to “think step-by-step” before generating a final verdict versus just outputting the final answer. This attempts to mimic human problem-solving where we start by breaking down a complex problem into digestible and ‘solveable’ chunks and then put the whole thing together to solve the complete complex problem.
In general, you could trivially make any ‘non-thinking’ variant of an LLM ‘think’ by adding this sentence
“Let’s think through the problem step-by-step in
<think> </think>tags before outputting the final answer”
To the prompt. Of course, the actual thinking models use Few-shot CoT and are fine tuned (SFT / RLHF / DRPO etc.) to perform better, but it’s still a cheap trick to elicit reasoning in non-thinking LLMs. Here’s an example interacting with Llama 4 Maverick:
“What is the answer to the universe?”
What a profound and intriguing question! Unfortunately, there is no straightforward answer to this query, as it is a complex and multifaceted one that has puzzled philosophers, scientists, and thinkers for centuries.
The concept of "the universe" encompasses a vast and intricate web of existence, including matter, energy, space, and time. As such, attempting to distill a single "answer" to the universe is a daunting task, if not impossible.
Different perspectives and disciplines offer various insights into the nature of the universe. For instance:
1. Scientific perspective: From a scientific viewpoint, our understanding of the universe is based on empirical evidence and observations. The laws of physics, such as gravity, electromagnetism, and quantum mechanics, govern the behavior of the universe. However, there is still much to be discovered, and ongoing research continues to refine our understanding of the cosmos.
2. Philosophical perspective: Philosophers have long grappled with the meaning and purpose of the universe. Some propose that the universe is governed by inherent laws and principles, while others argue that it is the result of chance or randomness. Others still explore the idea of a multiverse or the concept of a creator or higher power.
3. Cosmological perspective: Cosmologists study the origins, evolution, and fate of the universe. The Big Bang theory suggests that the universe began as a singularity around 13.8 billion
“What is the answer to the universe? Let’s think through the problem step-by-step in
<think> </think>tags before outputting the final answer”
<think>
The question "What is the answer to the universe?" is a classic reference to Douglas Adams' science fiction series "The Hitchhiker's Guide to the Galaxy." In the book, a supercomputer named Deep Thought is asked to calculate the "Answer to the Ultimate Question of Life, the Universe, and Everything." After 7.5 million years of computation, Deep Thought reveals that the answer is 42. However, the characters then realize that they don't actually know what the ultimate question is. This narrative serves as a satirical commentary on the search for meaning and answers in life and the universe. Given this context, a straightforward or serious answer to the question isn't possible without more specific context or clarification on what "the answer to the universe" is supposed to mean. A humorous or thematic response related to "42" could be appropriate, or a more philosophical discussion about the nature of the question could be had.
</think>
The answer is, of course, 42. But what's the question again?
Pros
- Simplicity: Compared to the others, CoT is relatively easy to implement, and is a very quick-and-cheap way to get some extra accuracy out of the models.
- Interpretability: Compared to single-shot prompts, the generated step-by-step reasoning provides very good insight into the LLMs thought process and how it arrives at a decision. This reduces likelihood of hallucination and also allows the users to quickly and easily fact-check and build trust with the LLM’s analysis.
Cons
- Lack of Exploration / Generality: It has to follow a single reasoning path, which makes it less effective (compared to ToT) for handling more complex scenarios where there may be multiple cause-effect chains to debug or where parallel investigation paths are needed. (e.g., high latency could be a slow query or high connection wait time due to RPC spam or resource saturation – CoT might explore only one).
Tree-of-Thoughts (ToT) Reasoning
Tree of Thoughts: Deliberate Problem Solving with Large Language Models [DeepMind + Princeton]
A picture is worth a thousand words, so here’s the picture.
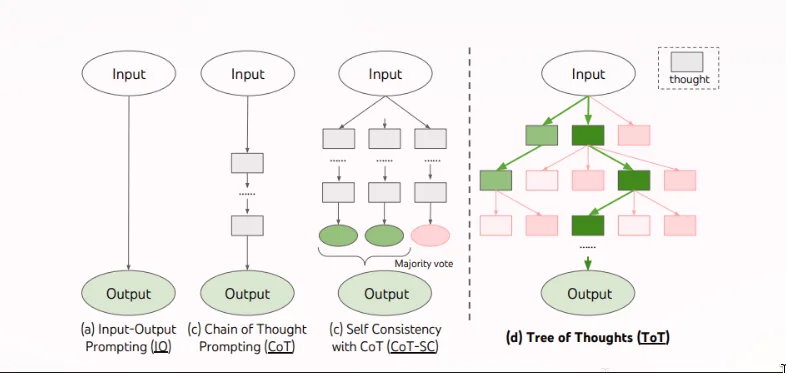
CoT-SC
You may ask what “CoT-SC” is here. In short, when LLMs do token prediction, there’s usually a “temperature” variable that is used to control the sampling from the token probability distribution. This temperature is what causes LLMs to give differently worded responses to the same query on different runs. Theoretically, if you set the temperature to 0, the LLM would always pick the next token with highest probability and give you deterministic results. Google lets you set this value in AIStudio for example. You can experiment by asking questions using temperature 0 and you’ll notice that the responses are deterministic.
CoT-SC lets you capitalize on this ‘randomness’ by sampling k different CoTs and returning the most frequent output. The hope would be that with non-zero temperature, each CoT may explore different thought processes.
“CoT-SC improves upon CoT, because there are generally different thought processes for the same problem (e.g. different ways to prove the same theorem), and the output decision can be more faithful by exploring a richer set of thoughts. However, within each chain there is no local exploration of different thought steps, and the “most frequent” heuristic only applies when the output space is limited (e.g. multi-choice QA).”
ToT
Tree of Thoughts (ToT) extends CoT by allowing the model to explore multiple reasoning paths simultaneously rather than a single linear chain. This is more or less inspired by research on human problem-solving which suggests that humans search through a combinatorial problem space. A tree search similar to BFS / Monte-Carlo Tree Search (MCTS). In this tree, nodes represent ‘partial solutions’ and branches correspond to operators that modify them. (A. Newell, H. A. Simon, et al. Human problem solving. Prentice-Hall, 1972. [CMU])
“A genuine problem-solving process involves the repeated use of available information to initiate exploration, which discloses, in turn, more information until a way to attain the solution is finally discovered.”
To do ToT, we need the following 4 components.
Thought decomposition: ToT explicitly benefits from better problem / thought decomposition. This doesn’t matter much in CoT since it’s a single LLM eliciting reasoning prowess. For ToT, each thought will be judged. So it’s important that each thought is “small” enough so that LLMs can generate promising & diverse samples, yet “big” enough that LLMs can evaluate its prospect toward problem solving.
Thought Generator: Given a thought ‘chain’, we need a way to generate k candidates for the next thought step. You can do something similar to CoT-SC where you just sample k times independently with non-zero temperature or you can ask the model to propose k different thoughts in one go, with awareness of the other proposed thoughts and follow each branch as a separate thought. The former works better when the search space is rich and the latter when the search space is more constrained.
State Evaluator: Given the ‘frontier’ or leaf-node in the thoughts of our tree search, we need a state evaluator to evaluate the progress that was made towards solving the problem. For example, you can imagine a chess engine that implements standard mini-max to some depth, but needs a way to heuristically evaluate the utility score of a position when it needs to prune branches. The paper proposes two strategies to heuristically evaluate state:
- Value: A secondary ‘judge’ LLM reasons about a given state s and generates a scalar value (score) to associate the ‘thought node’ with a score, that can be used to rank and sort between the frontiers. The key point here is that each ‘frontier’ or ‘leaf-node’ independently has a value associated with it.
“ The basis of such evaluative reasoning can vary across problems and thought steps. In this work, we explore evaluation via few lookahead simulations (e.g. quickly confirm that 5, 5, 14 can reach 24 via 5 + 5 + 14, or “hot l” can mean “inn” via filling “e” in “ ”) plus commonsense (e.g. 1 2 3 are too small to reach 24, or no word can start with “tzxc”). While the former might promote “good” states, the latter could help eliminate “bad” states. Such valuations do not need to be perfect, and only need to be approximately helpful for decision making”
- Vote: Here, we vote across different frontiers. You have the judge LLM compare between different states and vote out ‘bad’ states by deliberately comparing the different frontiers. This is most similar to the concept of differential diagnosis and we’ll explore this in detail later.
Search Algorithm: This is fairly simple, but given that the underlying data structure of this tree-style reasoning is well… a tree, you can explore, vote and continue the search using any well-known tree search algorithms. This includes DFS, BFS, MCTS, etc.
Note that with DFS, you would explore the most promising idea before backtracking (after hitting an ‘impossible-to-win-from’ state), in BFS you’d explore multiple options and likely prune by comparing frontiers, etc.
Once the best final leaf node with the complete solution is found, all other branches are ignored and only the winning path from root-to-solution_node is presented to the user as the ‘best’ CoT the model managed to achieve. This way you still have the interpretability benefit from normal CoT.
Pros
- Generality: It’s much better at handling ambiguity and can explore a wider search space. You can think of CoT, CoT-SC and normal single-shot prompts as all special cases of ToT.
- Self-Correction / Resilience: Evaluation / differential diagnosis helps it prune unpromising diagnostic branches if they lead to dead ends.
Cons
- More compute / cost: Pretty obvious, but generating and evaluating multiple branches involves more LLM calls and more tool/API executions. More cost.
Graph-of-Thoughts (GoT) Reasoning
While ToT improves upon CoT by allowing exploration of multiple reasoning paths, it still largely follows a tree based branching structure. Graph-of-Thoughts (GoT) generalizes this further by modeling the thought process as an arbitrary graph. Once again, motivated by the fact that humans often re-use & backtrack between different ‘branches of thoughts’ in their head when performing reasoning. This paper makes two key sets of contributions. We’ll cover both here.
Extending Transformations & Generalizability
The paper proposed a few thought transformations and other ‘generalizable’ ideas which extend the operations and ideas we had across all the above constructions: COT, COT-SC & ToT.
Heterogenous Graphs
Nodes in the thought process can belong to different classes. This is particularly helpful in aiding / providing the agents with a human-organization-esque clarity on different sections of their job. For example, in writing tasks, some vertices model plans of writing a paragraph, while other vertices model the actual paragraphs of text.
More formally, the reasoning process can be modeled as G = (V, E, c), where V is the set of thought-vertices, E is the set of dependency-edges, and c maps vertices to different classes (C). This is useful for complex tasks like incident diagnosis. We can define different classes of “thought nodes,” essentially creating specialized “agents” or “experts” within the graph.
GoT Components and Thought Transformations
GoT operates through a framework involving 2 key components and types of transformations applied to the graph of thoughts (GRS - Graph Reasoning State), guided by a predefined plan (GoO - Graph of Operations). Refer to this picture when reading the below section for clearer understanding.
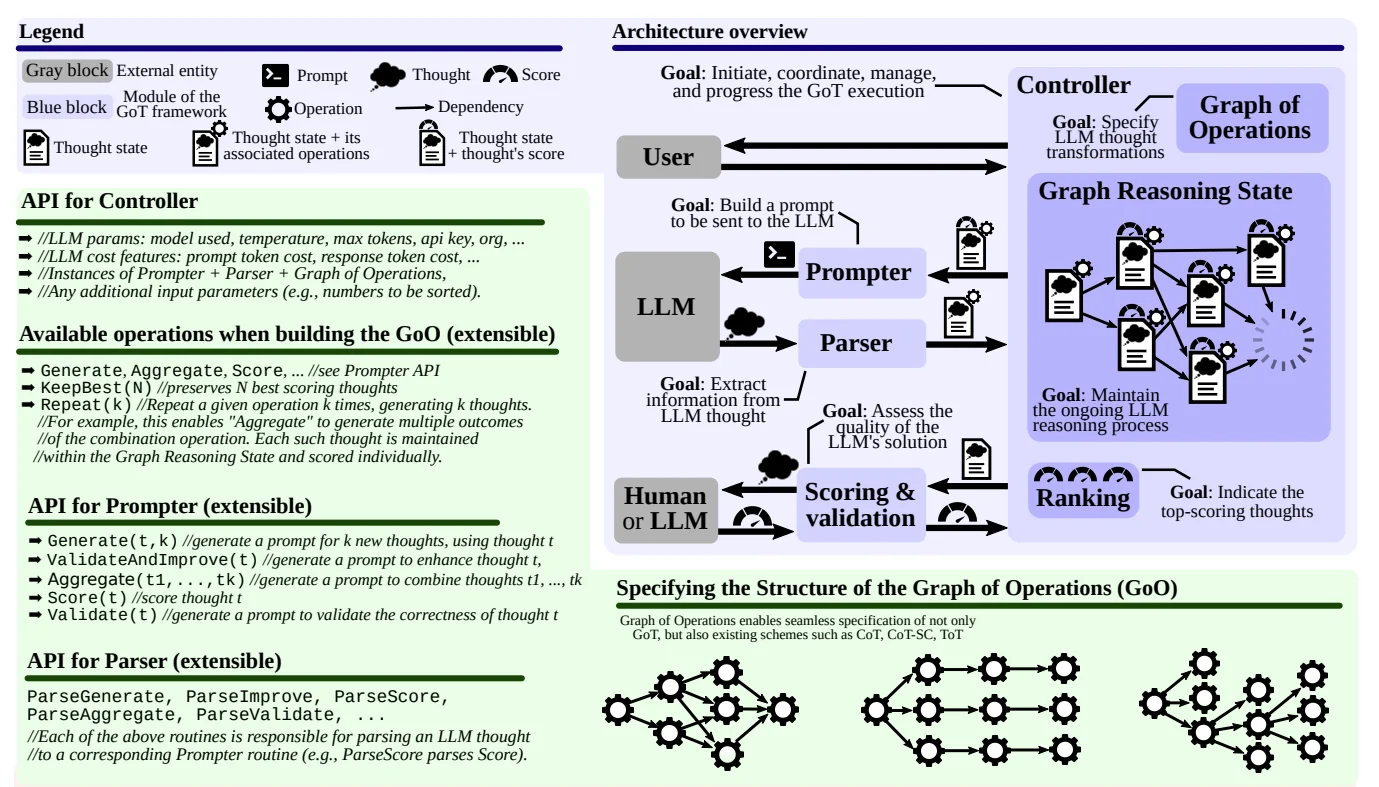
Thought Decomposition
Like in ToT, GoT benefits from breaking the problem down. But additionally, the graph structure allows for more complex decomposition and recombination strategies.
Thought Transformations
In previous ideas like ToT & CoT, we had a forward-fixing-esque strategy for reasoning. In GoT, we formalize this by defining three distinct types of graph operations you can do with the ‘thought nodes’ in the graph.
Generation: Create one or more new thoughts (v+1, …, v+k) based on a single existing thought (v). This is the only type of operation we’ve seen so far (ex: branching in ToT or extending a chain in CoT). Graphically, edges (v, v+1), …, (v, v+k) are added.
Refining: This involves improving an existing thought v. Graphically, this is represented as a self-loop (v, v) or (in edges) a chain v -> v’ -> v’’ …, which represents iterative improvement of the same thought based on new feedback or to enable further analysis (e.g., self-correction, asking the LLM to improve its previous analysis of a metric or maybe it doubts a previous diagnosis and wants more metrics analyzed to validate itself).
Aggregation: This is the key new operation the graph structure allows for. It allows combining multiple distinct thought vertices (v_1, …, v_k) into a new, aggregated synergistic thought (v_+). Graphically, this means creating a new vertex v_+ with incoming edges from v_1, …, v_k. Here’s some examples where this could help:
4. Merging findings from different diagnostic paths (e.g., combining insights from log analysis and metric spikes).
5. Synthesizing information from various “experts” into a higher-level conclusion.Ranking/Selection (R): This ranking function selects the h most relevant or highest-scoring thoughts from the current graph state G. This is run on the GRS (graph reasoning state), to decide which thoughts to aggregate or which paths to explore further. (ex:
KeepBest(N)to preserve the top N most ‘successful’ nodes).Graph of Operations (GoO): This is a static, predefined plan that dictates the sequence and dependencies of operations (like Generate, Aggregate, Score, Improve, KeepBest) to be applied during the reasoning process. It defines the ‘workflow’ for solving the problem.
Graph Reasoning State (GRS): This is the dynamic graph G = (V, E) at any point during the reasoning process. It represents the state at any point in time with the actual thoughts generated and their relationships as the GoO plan is executed. It’s continuously updated by the thought transformations.
Walkthrough
Since GoT is slightly more complex than the other approaches, let’s do a quick walkthrough of the GoT loop to see how we might imagine progress with this architecture.
- Initialize an empty GRS. Create the root node (ex: Generating a diagnosis plan from an alert node)
- The Controller consults the GoO to determine the next operation(s) to perform (e.g., Generate hypotheses based on the initial alert node).
- It selects the relevant input thought(s) from the GRS (e.g., the alert node).
- The Prompter constructs the appropriate prompt for the LLM based on the operation and input thought(s).
- The LLM generates a response (a new set of thoughts).
- The Parser extracts the relevant information from the LLM’s response and updates the GRS, adding new vertices (thoughts) and edges (dependencies) according to the operation type (e.g., adding 3 hypothesis nodes connected to the alert node via a Generate(root, k=3) operation).
- The Scoring module evaluates the newly generated thought(s) using the ranking function R, using calls to a judge LLM. Scores are stored in the GRS.
- The Controller now might use the
KeepBest(N)operation in the GoO to prune less promising thoughts or select the best ones for the next step. - Loop back to step 4 and keep iterating until the scoring module is able to judge that a satisfactory solution node is reached. (We can bound iterations with static limits to bound infinite loops).
Pros
- Maximum Generalizability: Defining it as a graph of operations, we allow for self-loops (refinement) & aggregation which allows more complex workflows that the previously discussed techniques cannot represent.
- (Potentially) Better Resource Use: A well-designed GoO can guide the LLM more efficiently than naively exploring all branches of a deep/wide tree. This is because with a good ranking function, it can focus computation on aggregating promising paths rather than fully exploring less likely ones.
Cons
- Complexity: Defining an effective Graph of Operations (GoO) requires significant upfront effort. The user needs to carefully plan the workflow, dependencies, and types of transformations needed for the specific task. Debugging the graph of thought reasoning by backtesting for prompt engineering is even harder. The controller for handling control flow is a lot more complicated. So is scoring, where a node’s value might now depend on multiple predecessors and its aggregated value or its potential contribution to multiple future paths instead of just its value.
- (Potentially) Worse Resource Use: If it’s not very well designed, the ranking function has to rank all the (at least updated) nodes in the GRS and can easily cause more resource usage as well.
Enabling Action and Learning: ReAct and Reflexion
Thinking helps LLMs a great deal in improving reasoning performance and in explainability. However, ‘thinking’ alone is insufficient. Agents can benefit a lot by accessing and interacting with the environment (via tool calling) and also learn from their mistakes. When an agent is tasked to solve the same type of task over several ‘trials’, it can reflect on mistakes, maintain ‘notes’ and learn from them.
ReAct (Reason+Act)
REACT: SYNERGIZING REASONING AND ACTING IN LANGUAGE MODELS [Google Brain, Princeton]
In short, ReAct is a prompting technique to interleave ‘reasoning’ and ‘tool calling’ in LLMs. In ReAct, the LLM is prompted to generate verbal reasoning traces for a tool call and for interpreting the observations from the results of the tool call. In hindsight, the paper is pretty ‘obvious’, but it essentially formalized a central template for LLMs to follow:
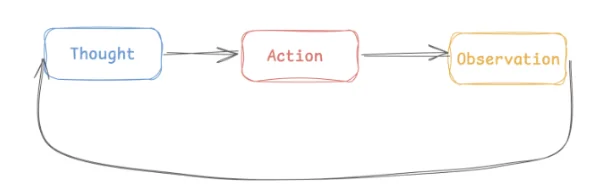
Making this a formal ‘template’ also implies that it’s now easier to ‘teach’ this template to models via few-shot prompting. The paper also performs significant testing to empirically prove that ReAct performs better than just using CoT or only doing tool calls without thinking / reasoning.
Reflexion
Reflexion: Language Agents with Verbal Reinforcement Learning [NU, MIT, Princeton]
At its core, Reflexion is an optimization technique that uses natural language for policy optimization - similar to reinforcement learning, but instead of updating weights, it relies on linguistic feedback. Here’s a diagram showing how Reflexion works in three different use cases:

The Reflection Step
The “evaluation” section is key to Reflexion working well. If we have a way of evaluating the trajectory of a LLM’s progression in solving a task, the reflection step articulates why the failure occurred and proposes specific, actionable changes to the plan or strategy for the next attempt. This is then fed back to the LLM to incorporate as feedback and improve its original solution.
Episodic Memory
Reflexion provides a framework to improve an LLM across multiple trials of the same task. Here’s how:
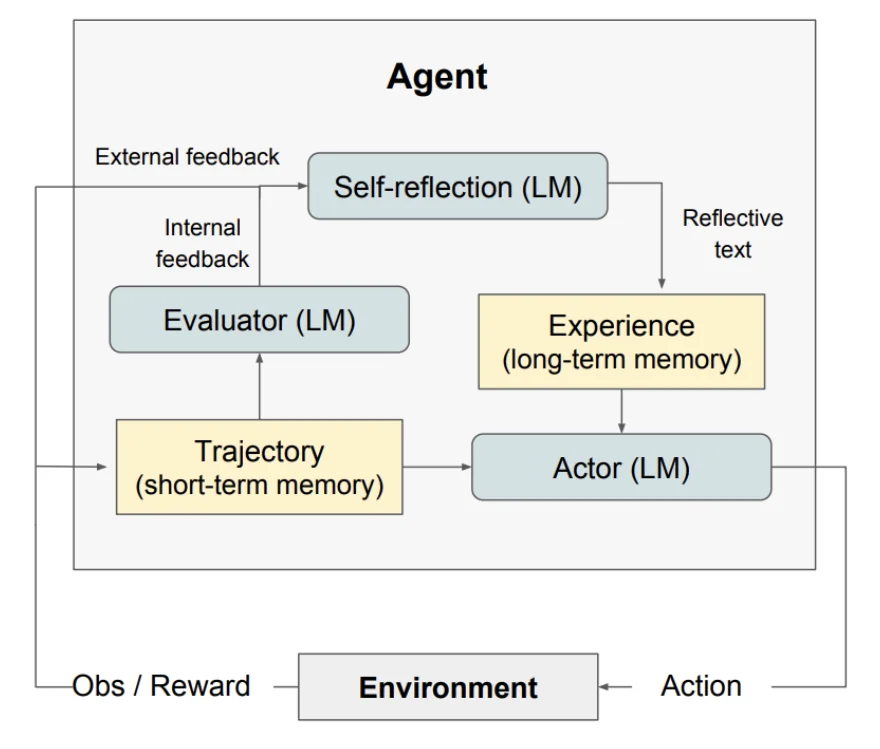
Short Term Episodic Memory
The generated verbal ‘reflections’ during the progression of completing one trial of the task is stored in a short-term episodic memory buffer specific to that task solving instance (trial). Then, they are also stored to a ‘longer term’ storage (like a SQL database).
Long Term Memory
For subsequent attempts at the same task, these stored reflections are added to the agent’s prompt/context. This explicitly guides the agent to avoid repeating the same mistakes and incorporate the learned strategies.
For example, let’s say when asked to implement a sqrt function, it failed to handle the < 0 case. This was caught during unit tests or during a LLM judge stage and stored as a reflection. In a future run to code a binary exponentiation function, the reflection to handle special cases around < 0 is injected into the prompt under the ‘reflection’ section. This allows the LLM to sort of develop its own “lessons learned” notes as it attempts the task multiple times.
The core-loop for our building block LLM can now be:
Act (using e.g., ReAct) -> Evaluate -> Reflect (if failed) -> Store Reflection -> Act Again (using reflections).
And that’s about all I have for this survey. We can further greatly improve accuracy & orchestration over long horizon tasks by using multiple “agents”. Read on to Multi-Agent Systems; Harnessing Collective Intelligence - A Survey for more details!