Towards a Completely Self-Driven DBMS - Challenges OtterTune Faced
Interactive Graph
Table of Contents
Abstract
This blog / set of notes is not based on a paper, but rather a set of talks given by the founders of OtterTune, describing their vision for the product and the challenges they had faced moving the OtterTune project from Academia to a sellable product. Not surprisingly, a lot of real-life problems surfaced when the product started being run in production environments. The goal of this blog is to explore Andy’s vision for a completely self-driving database, the challenges they faced with OtterTune, how they were forced to introduce a significant amount of manual work in their automatic pipeline to make things work, and maybe some thoughts on how we can try to get around that. The talks I am referring to are:
- OtterTune: AI-Powered Database Optimization as a Service! (Dana Van Aken)
- Andy Pavlo - OtterTune: Using Machine Learning to Automatically Optimize Database Configurations
- Why Machine Learning for Automatically Optimizing Databases Doesn’t Work by Andy Pavlo - JOTB23 Note that I assume that you’ve either read the original OtterTune Paper or my blog on it OtterTune - Automatic Database Management System Tuning Through Large-scale Machine Learning. If you have, you’ll already know why this is such a difficult problem to solve & why solving it would make a lot of less expensive & faster for all Database maintainers.
What Can Be Optimized?
What we want to have is a completely external & automated service. One that can hook onto any external database (including sharded like cockroach). Everything in the pipeline must be automated. All the points listed below sort of fall into the same bucket in that you want to automate the tuning of these properties to speed up execution of your SQL queries. All of these are difficult to deterministically optimize and we have grown to rely on machine learning heuristics to optimize these properties.
Indexes
Deciding on the set of indexes to maintain can be a challenging task. The more indexes you maintain, the more queries you can make run faster. However, keep too many indexes and all your write operations will have to perform updates on multiple indexes, slowing them down by a significant amount. There has been a significant amount of work in this field, something I plan on exploring soon. Recommended papers:
- Automatically Indexing Millions of Databases in Microsoft Azure SQL Database
- Oracle Autonomous Database Service
- Demonstrating UDO: A Unified Approach for Optimizing Transaction Code, Physical Design, and System Parameters via Reinforcement Learning
- openGauss: An Autonomous Database System
Partitioning
The linked paper is regarding finding an optimal sharding scheme for the database in a Cloud environment.
Knob Configuration
With time, the number of configurable variables or “knobs” exposed by the developers of popular DBMS software has risen. Depending on your workload, tuning these parameters from default to the optimal configuration can lead to much better utilization of hardware & give significant cost and speed benefits to DBMS workloads.
- Automatic Database Management System Tuning Through Large-scale Machine Learning / OtterTune - Automatic Database Management System Tuning Through Large-scale Machine Learning :)
- An End-to-End Automatic Cloud Database Tuning System Using Deep Reinforcement Learning
- Akamas
- ResTune: Resource Oriented Tuning Boosted by Meta-Learning for Cloud Databases
- QTune: A Query-Aware Database Tuning System with Deep Reinforcement Learning
Query Optimization
MySQL query optimizers are known to be notoriously bad. But providing the right hints & suggesting better execution plans to said optimizers can also lead to huge increases in hardware utilization.
- Bao: Making Learned Query Optimization Practical
- Neo: A Learned Query Optimizer
- MySQL HeatWave Goes on Autopilot Delivering Automated Real-Time Query Analytics Faster, Cheaper
OtterTune: Challenges in Transitioning from Academia to Industry
The efficacy of ML algorithms for tuning databases in research literature are impressive, but there are many assumptions made in the papers which allow it to obtain those numbers. However, while the academic project only focused on configuration knobs, the commercial project had expanded to include knobs, indexes, cloud configurations & queries.
Assumption 1: Availability of Training Environments Mirroring Production Exactly
One of the biggest pain points they faced when optimizing production databases is that the paper assumed the availability of a training environment that mirrors production exactly. One might think that companies might maintain such staging environments, but the truth is that the staging and dev environments are often on much smaller instance configurations (for saving costs) and do not face a workload identical to that faced by their production counterparts. An ML algorithm trained on this configuration will do excellent in staging, but may perform very poorly when moved to production. Sometimes you also have features like dynamic hardware scaling (burst credits) that allow the servers to crank up CPUs during random short intervals which might throw off your readings by quite a bit.
In one of their field studies,
Customer $X$ got a $15\%$ reduction in Aurora PostgreSQL IOPS in their staging DB, but only $1\%$ when applying the same optimizations to prod DB.
Assumption 2: Availability of Tools for DBAs to Replay Workload Traces in Identical Environments
Even if the company had identical staging & production environments, the two databases are often under very different loads. The staging database might be used much more sparingly in comparison to the production database. “Replaying” a trace becomes a difficult problem to solve. To carry out such a task you’d need to log the time of arrival of queries and then mirror this execution as a replay trace on the copied staging database. Further, without a repeatable workload as a baseline, it is difficult for ML models to learn whether they are improving a database.
- Tools for open-source DBMSs are less sophisticated than commercial DBMSs.
- Existing built-in slow query log methods do not capture transaction boundaries.
One of the best solutions to this problem identified so far was how Oracle did it.
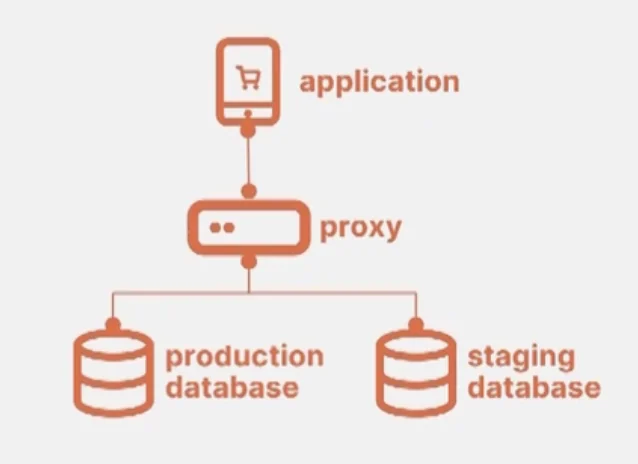
By having two identical instance replicas of the database and a proxy at the application level which mirrors the traffic to both the databases, you have a very reliable and identical measure of the workload that the production database has to process.
Regarding repeatability, the product moved from the 5-minute monitoring period mentioned in the paper to use a much larger 1-day window for monitoring. This presumably is long enough to learn the general characteristics of the workload, even in a distributed setting where the placement driver may schedule queries to different nodes differently at a higher layer.
Further, to build generalizable models and transfer experience, they needed training data for a diverse set of workloads, hardware & software configurations $\to$ They needed a strategy change.
Assumption 3: Users Know What Their Databases Are Doing / Models Working In Isolation
Sometimes, bugs in the CI/CD pipeline could cause random spikes in usage which the company might need days to debug and track down. If the humans are unable to immediately identify the cause of the issue, the model does not know this either and might start incorrectly tuning the query since the function landscape captured during that period would be significantly different from what it is supposed to otherwise optimize.
Further the OtterTune software work on isolated database nodes. If two databases are working as replicas of each other or sharing similar data, it is definitely useful for an automated tuner to know that two databases are replicas and that they might benefit greatly from starting at the same configs instead of wasting expensive time & resources retraining.
Assumption 4: Optimization process is a one-time, offline activity
To some extent I believe this was pitched as an assumption partly to convince customers to not use OtterTune as a once and done tool. That said, it is true that depending on the service the customer is providing it is possible that there will be moments in time where the workload might change significantly enough to warrant another optimization bout with OtterTune. I highly doubt it ever happens frequently enough to run OtterTune very frequently, but let’s suppose the customer decides to change his architecture, the backend, handle an influx of customers, etc. all of which are common in developing startups (and even much bigger startups), it would be worthwhile to re-run OtterTune. But this opens up another can of worms in that you now need to solve another open problem, “When has a workload shifted enough to warrant running OtterTune again?” This is a monitor, detect and alert problem which they pose as an open problem to solve in the future.
Other Problems
Safety
You do NOT want to crash your customer’s production database at any point in time. If you are tuning on a production database, you have to be very careful not to degrade performance by enough to either mess up readings or crash the server. Stability is a lot more important to most customers than peak performance.
Time-To-Value Selling Proposition
How do you convince a customer that running OtterTune for just days is sufficient to show significant gains? What if it takes weeks? Without a repeatable workload the time-to-convergence could take a much longer time to converge on a near-optimal configuration. This was one of the reasons why OtterTune also diverted to providing health checks, index optimization suggestions, etc. They had to provide value faster.
OtterTune: Solutions (or “Keeping it Street”)
Solving Safety
As a consequence of getting around the first two assumptions they made, they realized that running OtterTune on production databases was the only real solution for many of their customers who did not have the relevant tools & stack to setup a perfect traffic replication system like Oracle. In these scenarios, the only solution was to run OtterTune like a side car attached to production. This obviously has major safety risks. Here’s how they tackled it:
- Provide a significant amount of manual control for:
- Tuning Periods: Allow DBAs to schedule exactly when the DBMS will run tuning workloads, collect samples, etc.
- Human-In-The-Loop-Approval: Allow DBAs to manually verify all the changes that OtterTune was making before applying. This also required making the changes more human understandable. The team leveraged a mix of GPT generated & human hardcoded descriptions of knob changes to also explain what the changes OtterTune was making did and why it thought doing it was correct.
- Restart Tracking & Scheduling: Allow DBAs to schedule exactly when the DBMS will restart. This allows them to ensure that it happens when they are doing non-important stuff and that they are available to monitor it closely following the restart.
- Knob Limits (External Factors): There may be instances where the DBMS might share the host machine with other software in un-containerized environments or similar where there are factors outside of OtterTune’s control. For example, companies may want to (in instances where extreme reliability is paramount, medical software for example) limit memory usage to say $60\%$ of all available memory even though the recommended might be $70\%$. So it was important to make allowances for DBAs to provide a safe range between which OtterTune was allowed to tweak the knob. It cannot exceed or undercut this range under any circumstance. Trade performance for (even if it is only perceived) reliability.
Fleet Management
People have a lot of databases. Often it’s just the same database with the same workload just duplicated and sharded across many regions. In these scenarios you really don’t need machine learning. It makes a lot more sense to just identify that these two tables are the same logically (even though they are two separate physical instances), by comparing schema, name, etc. and then applying the config that was trained in one location in the other place too. In one of their field studies, they noticed that the same table was $10\times$ faster in one region than the other. Upon manual debugging, they discovered that the DBA had forgotten to build an index built in the faster region in the slower region. These mistakes don’t need machine learning to solve, but they still need to be identified and solved.
Providing Peace of Mind
This I believe was somewhat of a pivot for OtterTune to solve the “optimization is a once and done” problem. Reliability is a lot more important to customers than performance. So provide health scores & performance tracking to ensure that customers use the product and also have an abstracted out easy-to-see score to see how “safe” and reliable their database is. I believe integrating something like Netflix’s Simian Army with automated runs of their monkeys would be useful integrated into such a health-scoring system.
Give Up & Integrate Manual Help
Knob Selection
Domain knowledge is still very valuable to help the software at the moment since the sheer amount of data for each configuration that we need recorded previously is a lot more than what is available in public today. You can think of it as doing machine learning in an era before social media and the internet. Without the “big data” collected for this purpose, it is very difficult & time consuming for OtterTune to carry out the optimization without manual Domain Knowledge.
The configuration search space is very high-dimensional. However, research shows that $\lt 20$ knobs can achieve near-optimal performance and expedite the tuning process. We can manually mark knobs that don’t make sense to tune, require human judgement, or require database restarts. Further, in two years, nobody ever turned on tuning any of the knobs that needed database restarts. So they swept this under the rug even though they could support it. They combined the Lasso & SHAP techniques that they previously used with domain knowledge from PGTune, Percona Blogs and other DBMS manuals to make reducing the search space more efficient.
Recommend customers to only use 10-20 knobs to start tuning. Adding all knobs to the search space for tuning makes the program extremely inefficient while not making any significant gains in comparison.
Config Selection
Instead of starting with only the closest workload that was mapped in the workload characterization step, especially early on in the loop, try “generally good” knob values recommended by heuristics like PGTune or MySQLTuner. Adding these to the search space at the start of the tuning session helps bootstrap the process. Further, integrate periodically choosing settings based on data-driven recommendations. Example: If buffer cache hit ratio is low, increase the buffer pool size.
In short. They had to give up on the completely automatic solution in favor of quickly resolving customer issues by leveraging domain knowledge & integrating it with their product to provide a seamless experience to their customer.
OtterTune: Performance Improvements & Success
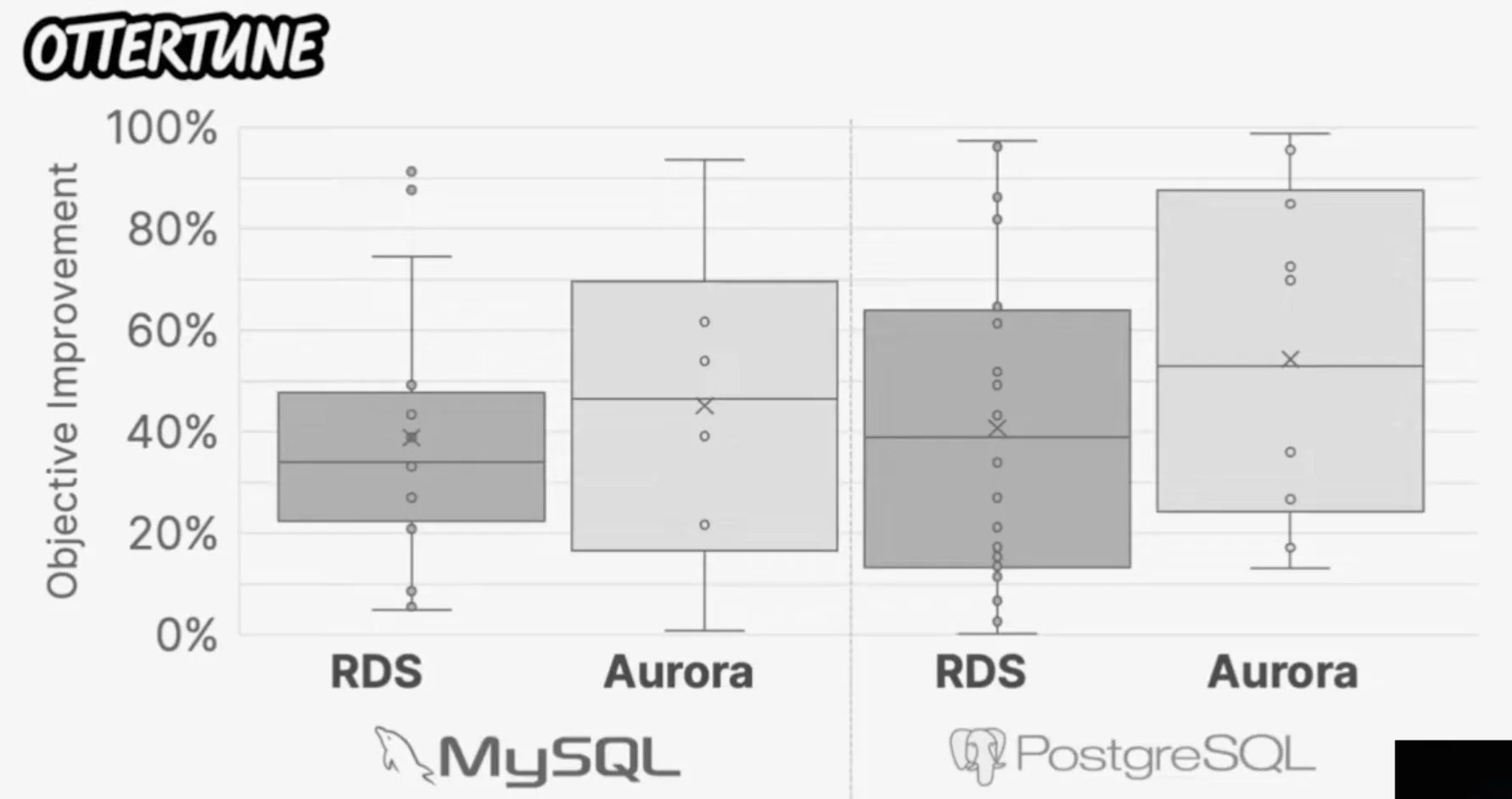
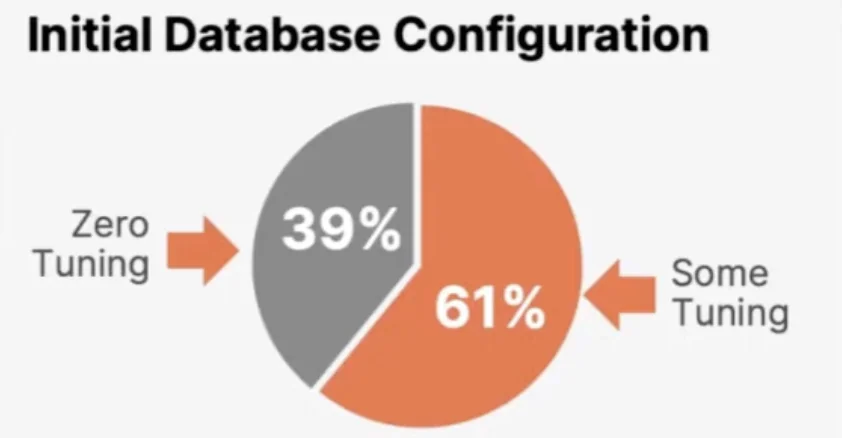
- OtterTune: AI-Powered Database Optimization as a Service! (Dana Van Aken) Given that $61\%$ of their customer did attempt to tune the database, OtterTune was able to get significant performance improvements. Further, Andy claims that a decent number of the databases at the bottom of the scatter plot are dead databases which just did not have enough queries being bed to it to notice any performance increase since they were dormant for the majority of the time anyway. Dana does mention that some of them were likely very well Tuned databases too.
OtterTune: Field Studies
French Bank
The bank had 1000 Postgres instances they wanted optimized. But when they actually went to look at the databases they realized the number of actually used databases was one. Due to political reasons saying you’ll have a “database” for your service made certain approvals easier and this bad practice just took over the bank and they had a 1000 useless database instances.
They came back saying they’re a primarily Oracle DB which had been manually tuned by their expert DBAs. Minimal work had to be done by the OtterTune folk on the driver & data transformation side, but all the ML algorithms used remained the same. This is what they meant when they wanted this service to be truly plug and play on-top of any DBMS provider. This is even considering that the bank wanted to optimize something called “Oracle DB Time” which is an arbitrary user-defined metric for OtterTune, but due to how the ML algorithms were defined, it could seamlessly be supported.
The shared disk had crazy variance. Had to manually be handled.
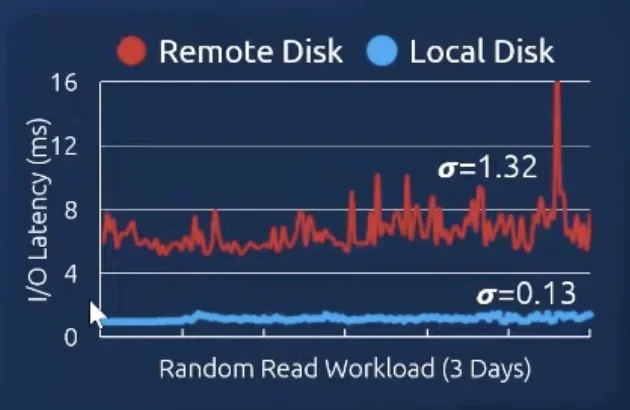
Results: They managed to get Oracle’s resource consumption down by $50\%$.
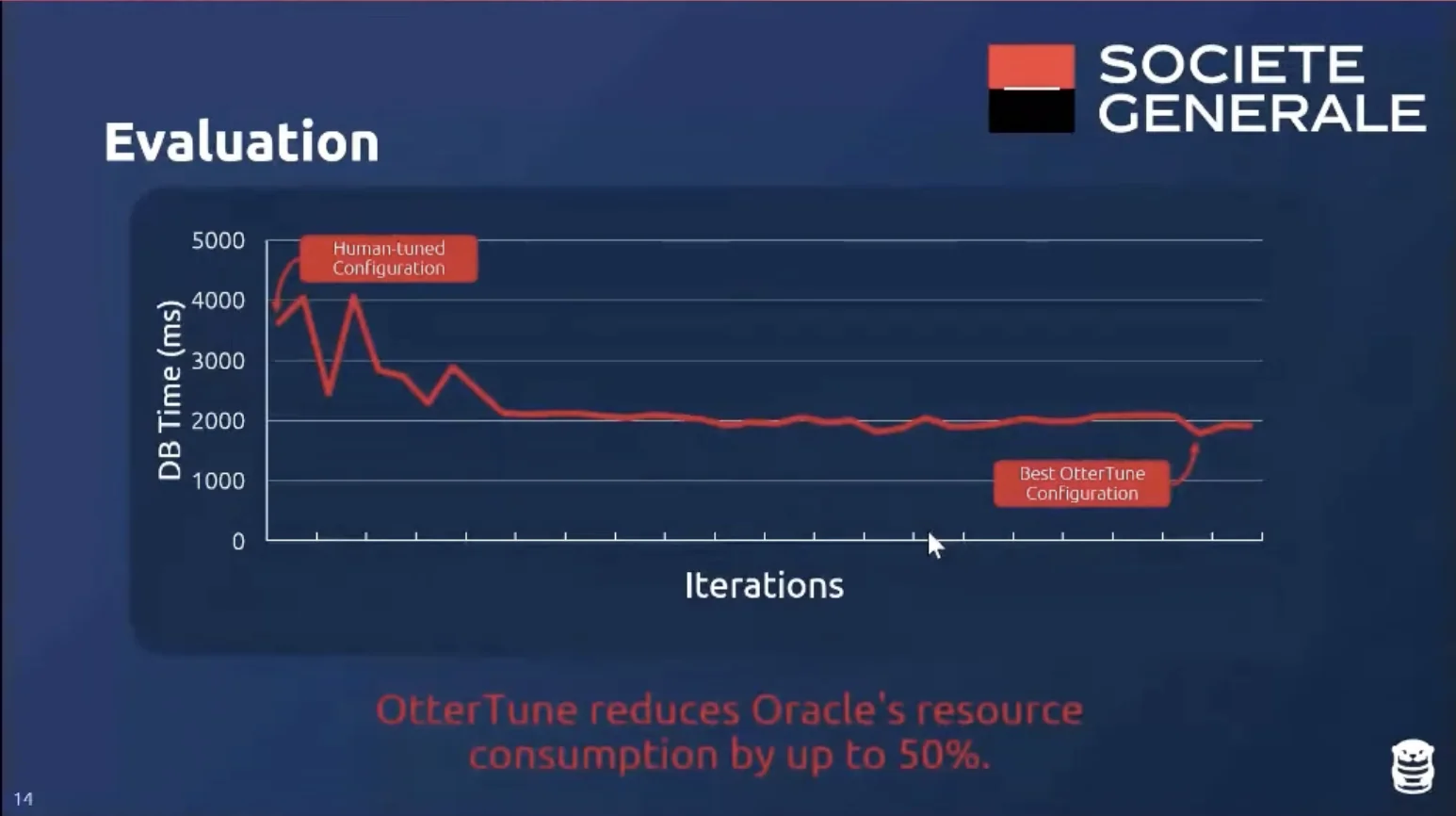
Lesson Learned - Experts Make Mistakes: The DBAs had tuned the DBMS before upgrading from Oracle v11 to v12. They did not check the configuration after the upgrade. This is why automation is very useful to catch these changes & correct them. Lesson Learned - Dealing With Bad Configurations: With little prior data, algorithms may choose bad configurations that may cause:
- Extremely slow query execution (Cut the query execution half way through when we know the data gained from it is redundant anyway?)
- DBMS fails to start: In practice, they realized that returning say $2\times$ the worst recorded value so far was good enough to make the algorithm converge on a very efficient / optimal configuration.
- DBMS fails after delay: This is trickier to solve. For example, mid-run memory allocation which breaks the server. They were able to solve by scraping the log and identifying these errors. Again, once identified, just give it a very bad score like in the previous scenario and the algorithm performs without any issues.
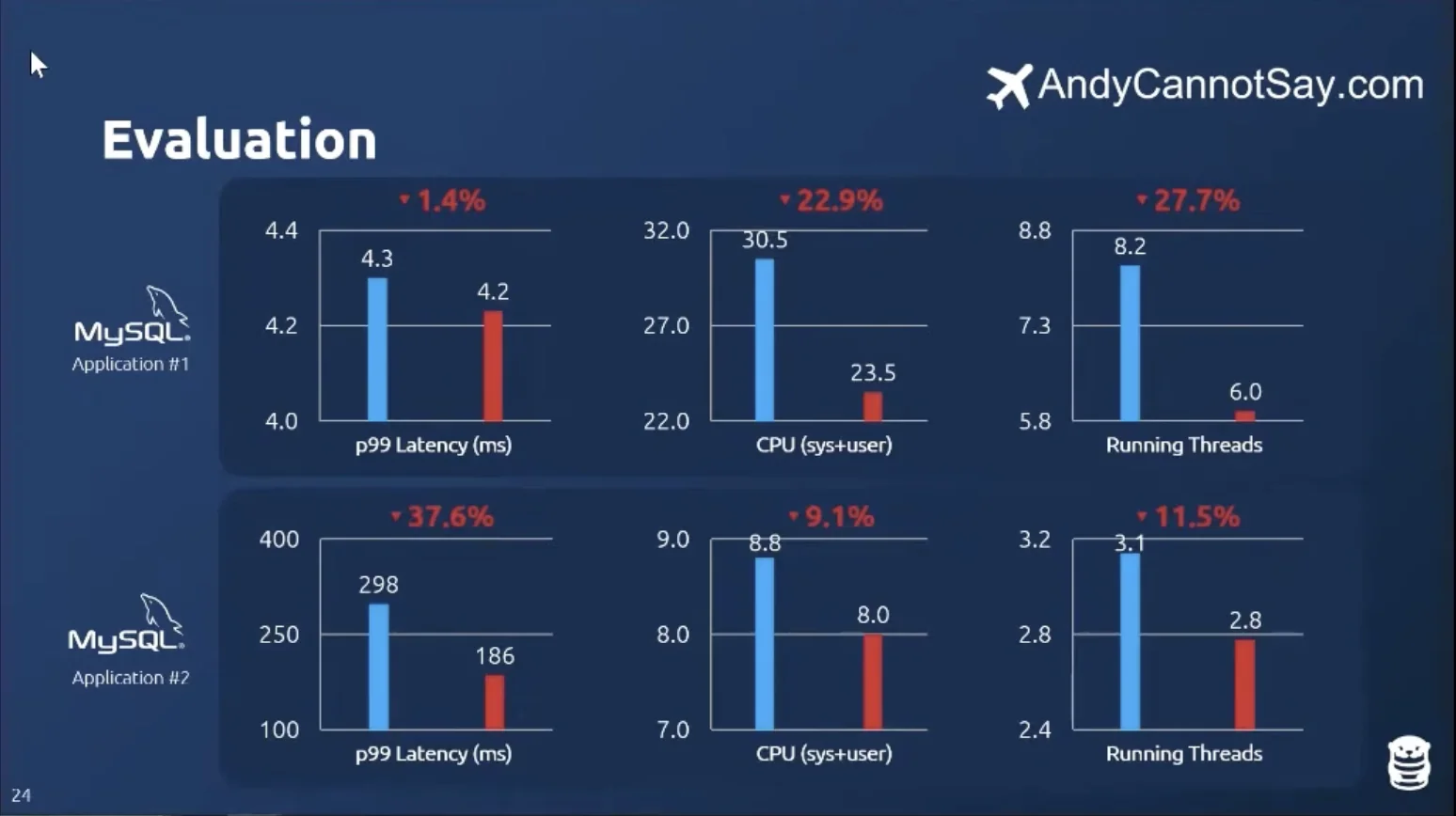
Unnamed Travel Company
They had a very read-heavy workload & wanted to tune their read-replicas. They currently generate configs using in-house formulas based on hardware specifications with manual tuning from DBAs if required. They tuned using 20 knobs for OtterTune.
Results:
Open Problems
Workload Synthesis
Like mentioned previously, mimicking production database traffic is not an easy problem to solve for most customers. Can we perhaps solve it by using generative models like Dall-E, etc. to synthesize these workloads to exercise the staging database just like the production database?
- Relevant Paper Suggested: HyBench: A New Benchmark for HTAP Databases
Sample-Efficient Tuning Techniques
How do we speed up the model to collect fewer samples & converge faster? Can we modify the internals of MySQL & Postgres, etc. to terminate query execution early even in the middle of data collection? If a query has been running for half an hour but the data collected is already enough to identify that the data is redundant, can we cut early and give “infinity” or “very bad” feedback to the model and save costs?
- Relevant Paper Suggested (Highly): LlamaTune: Sample-Efficient DBMS Configuration Tuning
Student suggests checking out transfer learning for instance optimization that can cast these workloads into large vectors which apparently works reasonably well for workload mapping. Andy says hardware and instance differences are an issue but the paper is for a fixed instance anyway? But Dana does say that they do not use the average difference of metrics method used for workload characterization in the paper in the production model. We do need more data, whether from the EXPLAIN plans or similar to improve workload characterization.
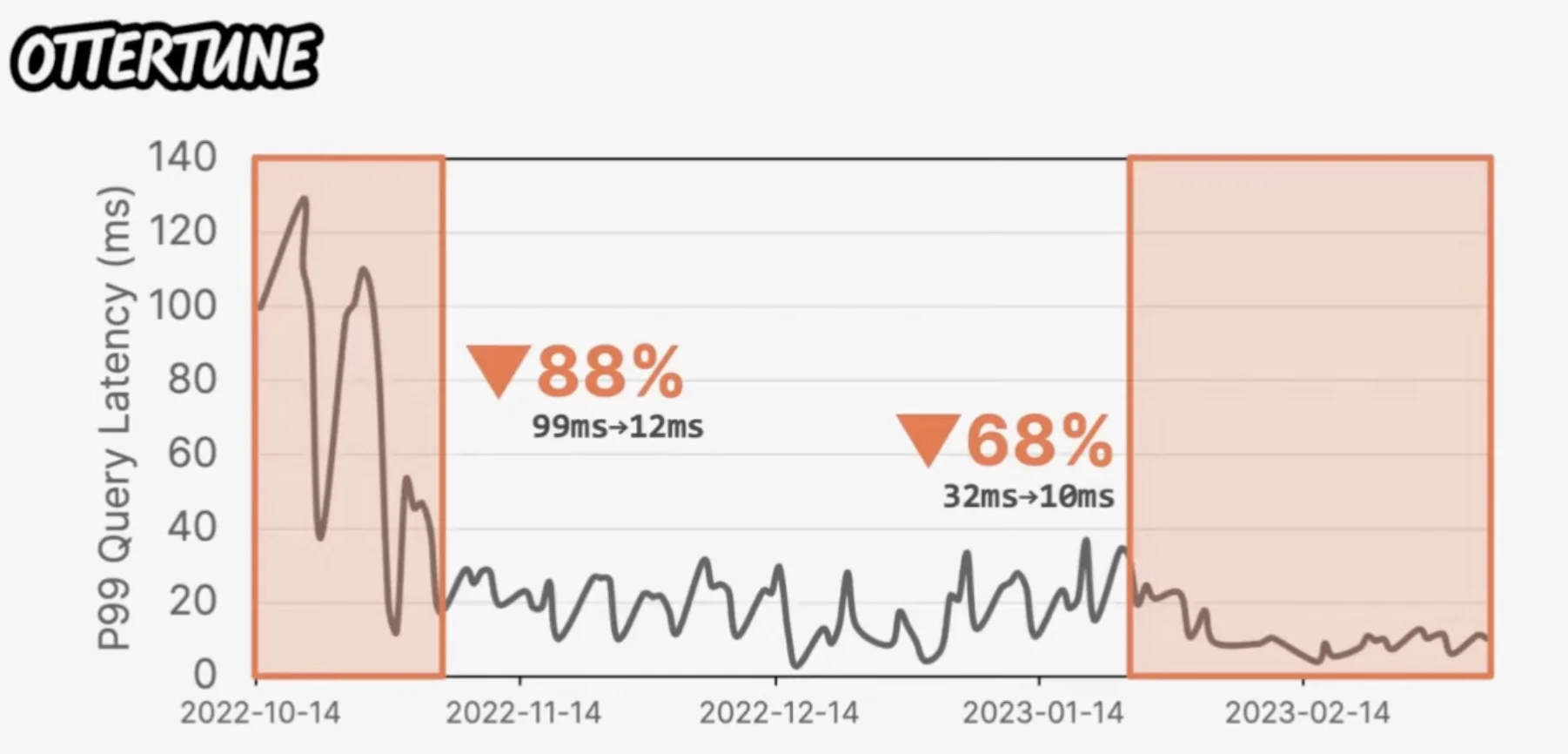
Stopping / Starting Criteria
Application Development Integration
A suggestion is to integrate with CI/CD, GitHub, etc. to identify PR changes to indexes etc. and catch these errors early on in the pipeline way before it makes it all the way to production.
Extending Beyond DBMS Config Optimization
Making instance size optimizations & even RDBMS software would be great. But lack of data is a very hard problem.